Advanced Natural Language Processing Techniques
 Admin
Admin


Summarise with AI:
The ability to extract meaning from language is no longer confined to humans. Natural language processing solutions can interpret text, structure it, and act on it using advanced processing techniques. This shift is redefining how businesses engage with information. From customer queries to operational documents, language data exists in abundance, yet most of it remains unstructured. Unlocking its value requires more than basic automation. It calls for deliberate, scalable NLP strategies.
These techniques now power systems that anticipate search intent, generate smart email replies, and scan thousands of customer reviews or support tickets. The progression from rule-based tools to modern NLP methods reflects a move toward intelligent processing.
As more software products integrate language-based capabilities, understanding core NLP methods becomes essential. This article explores fundamental techniques, how they function, and where they can be practically applied in development work. The focus is especially relevant for teams building platforms that work with unstructured or user-generated content.
Whether you are refining an internal analytics system or developing a multilingual chatbot, these approaches provide a foundation for deriving value from language at scale.
What Is Natural Language Processing (NLP)?
Natural language processing is a way to help software make sense of human language. It allows systems to read, organize, and respond to text or speech in a structured way.
Instead of relying on keywords alone, NLP breaks language into parts like grammar, sentence structure, and meaning. This makes it possible to extract useful information from emails, reviews, documents, or chats. It also helps software handle language that is messy, informal, or inconsistent, which is often the case in real-world data.
Earlier methods used fixed rules to process text. Most systems today rely on examples and statistical models that improve with more data. This makes NLP more flexible and accurate for tasks like sorting messages, tagging content, or detecting intent.
For software teams, NLP offers a way to deal with large volumes of unstructured text. It can be used to group feedback, prioritize support tickets, scan resumes, or power search features. The goal is not to replace human understanding, but to support it at a scale that manual work cannot match.
Key NLP Techniques for Text Processing
Natural language processing involves a range of techniques that allow software to work with language in structured and meaningful ways. These techniques help transform raw text into data that can be analyzed, categorized, or acted upon. While some methods focus on cleaning and preparing text, others dig deeper into meaning, context, or intent.
Each technique plays a specific role in solving language-related problems. For development teams, choosing the right combination depends on the task—whether it is classifying documents, detecting tone in feedback, or summarizing long reports.
Below are 8 NLP methods commonly used in real-world applications, especially where large volumes of text data need to be processed at scale.
1. Tokenization
Before language data can be analyzed or interpreted, it must be broken down into manageable parts. Tokenization is the step that makes this possible. It takes raw text and splits it into smaller elements, typically words or characters, that can be processed by software.
This step is often where unstructured language first becomes structured data. For example, a product review or support message is segmented into tokens, allowing further tasks like classification, filtering, or sentiment detection to take place.
There are different ways to tokenize text. Word-level tokenization is common when working with user-generated content. Character-level tokenization is useful in systems that need to handle typos or languages without clear word boundaries. Some models use sub word units to deal with rare terms or variations in spelling.
Example: Tokenizing Input
Consider the sentence from a system log:
"Payment failed for user ID 24819 on March 12."
A word-level tokenizer would split it into:
['Payment', 'failed', 'for', 'user', 'ID', '24819', 'on', 'March', '12', '.']
If a subword tokenizer is used, you might get:
['Pay', '##ment', 'fail', '##ed', 'user', 'ID', '24819', 'March', '12']
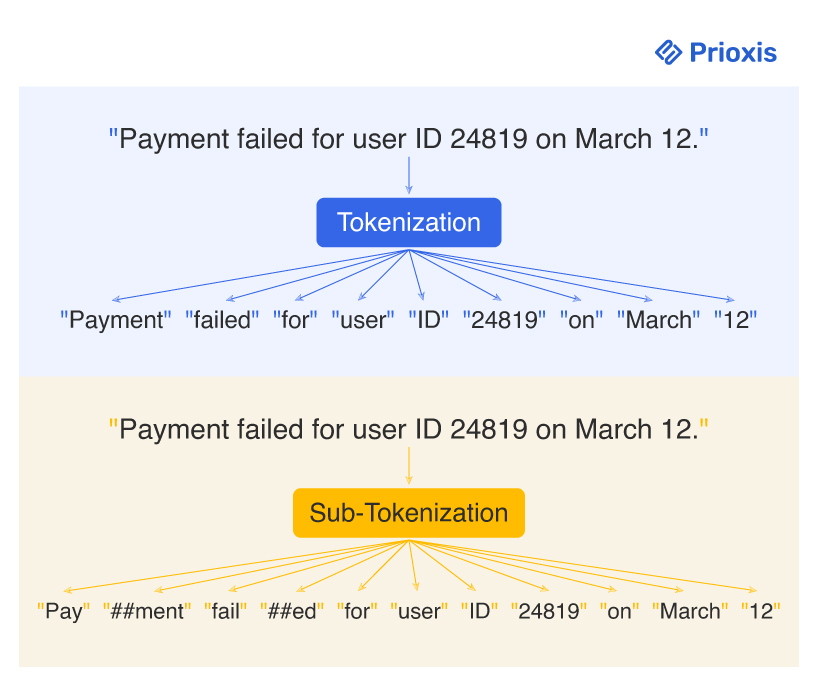
This level of segmentation allows software to generalize across variations like “failing,” “failed,” and “fails” without needing separate rules. It is especially useful when building systems that classify logs, detect errors, or group similar user issues across different phrasing styles.
In development workflows, tokenization is part of the preprocessing pipeline. Whether the end goal is to power search results, feed a model, or normalize input across languages, this step lays the groundwork. Its simplicity hides its importance — most downstream natural language processing techniques depend on getting this part right.
2. Keyword Extraction
Keyword extraction is the process of identifying the most meaningful words or short phrases in a piece of text. These terms often reflect the key subject or intent of the content and are used to surface important patterns without reading full documents.
Unlike text classification, which assigns categories to content, keyword extraction simply highlights what stands out. It is frequently used in early-stage analysis, especially when reviewing user feedback, chat transcripts, or open-ended survey responses.
In a support system, for example, teams might process thousands of tickets per week. Keyword extraction can highlight recurring terms like “billing error,” “password reset,” or “cancel subscription.” This helps product teams prioritize issues without reading each ticket individually.
There are different approaches depending on the complexity of the task. Simpler methods might count word frequency after removing common stop words. More sophisticated ones measure term significance across documents or use graph-based scoring models.
Example: Extracting Keywords from User Feedback
Take this feedback from a mobile app review:
"The login process is slow, and the app crashes when I try to reset my password."
A keyword extraction system might return:
['login process', 'slow', 'app crashes', 'reset password']
These keywords help product teams quickly understand the core problems mentioned, without needing to scan each review manually. When aggregated across thousands of entries, repeated terms can signal systemic issues or feature priorities.
This technique is also used to improve content discovery. In internal tools, it helps tag documents or surface relevant articles. In customer-facing platforms, it improves search accuracy by connecting user queries with actual content themes.
3. Lemmatization and Stemming
Lemmatization and stemming are two techniques used to reduce words to their root form. This makes it easier to group related terms and simplify language data before further processing.
- Stemming works by trimming word endings using predefined rules. For example, “running,” “runner,” and “runs” might all be reduced to “run” or even “runn” depending on the algorithm. It is fast and often sufficient when exact grammar or spelling is not critical.
- Lemmatization takes a more precise approach. It uses dictionaries and part-of-speech tagging to return the correct base form of a word, known as a lemma. For instance, it maps “went” to “go” and “better” to “good,” which a basic stemmer cannot handle correctly.
In LLM product development, the choice between the two depends on the task. If you are building a search function or classifying user queries, lemmatization offers better accuracy. If speed is more important than perfect form, stemming may be a practical alternative.
Example: Comparing Lemmatization and Stemming
Consider this user input in a support form:
"I was running late because the system crashed again."
A stemmer might reduce this to:
['I', 'wa', 'runn', 'late', 'becaus', 'the', 'system', 'crash', 'again']
A lemmatizer would produce:
['I', 'be', 'run', 'late', 'because', 'the', 'system', 'crash', 'again']
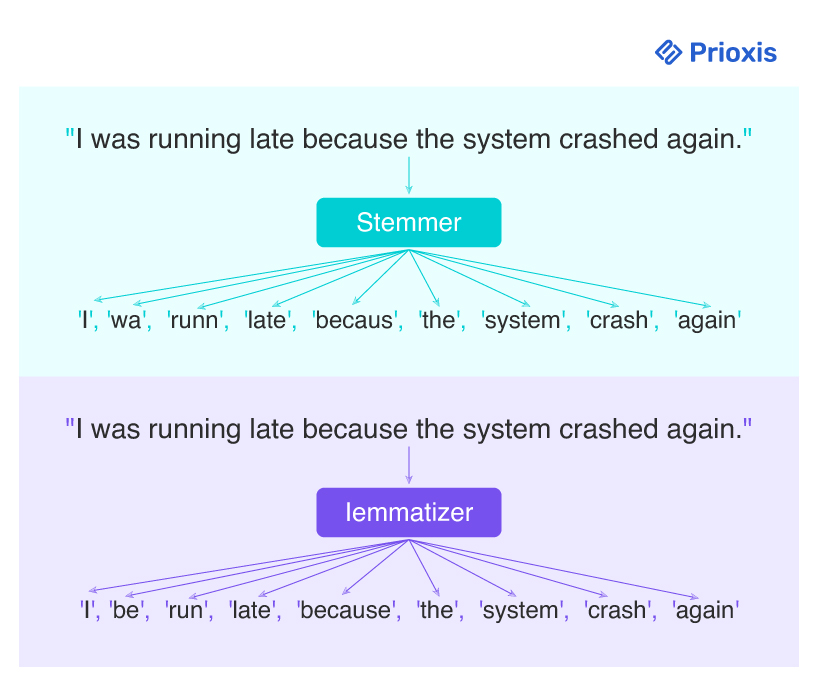
In this case, lemmatization retains proper word forms and improves downstream accuracy especially in models designed to understand intent or summarize content. The stemmed version is faster to compute but introduces distortions that may reduce clarity or consistency in output.
Both methods help consolidate language variation. This is essential in use cases like grouping duplicate issue reports, simplifying content for analytics, or matching queries to documents in internal tools.
4. Text Summarization
Text summarization is the process of reducing a longer body of text into a shorter version that retains the core meaning. It helps teams extract key insights without having to read every sentence in full.
There are two main approaches.
- Extractive summarization selects important sentences or phrases directly from the source text.
- Abstractive summarization, on the other hand, rewrites content in new phrasing, aiming to convey the same message more concisely.
The second method requires deeper language understanding and is typically used when tone, clarity, or grammar need to be improved in the final output.
In a business context, summarization is valuable when working with long documents, such as meeting transcripts, compliance reports, or research articles. It allows stakeholders to focus on the highlights rather than navigating through hundreds of pages.
Example: Summarizing System Logs or Reports
Imagine a daily system report containing several pages of activity logs. Instead of reading the entire file, a summarization pipeline could return:
"Multiple payment timeouts occurred after 9 PM. Retry attempts increased latency. No critical service failures reported."
This gives operations teams a clear, actionable overview without combing through detailed entries.
From a development perspective, summarization often builds on earlier NLP steps like tokenization, keyword extraction, and classification. When combined effectively, it can automate review processes, power executive dashboards, and support real-time content filtering.
5. Named Entity Recognition
Named Entity Recognition, or NER, is the process of identifying specific types of information within a block of text. These typically include names of people, companies, locations, dates, and monetary amounts. Once identified, each entity is assigned to a predefined category, allowing the system to structure language data in a way that is easier to analyze and act on.
This technique goes a step beyond keyword extraction by not only identifying relevant terms but also labeling them by type. Let’s take a sentence that could appear in a financial news article or investor report:
“Tesla announced its Q2 earnings on July 19 during an event held at its Austin headquarters. Elon Musk highlighted revenue growth and supply chain improvements. The report also referenced Tesla's expansion into India and a new battery partnership with Panasonic.”
NER would extract:
- Tesla as an Organization
- Q2 earnings as an Event
- July 19 as a Date
- Austin as a Location
- Elon Musk as a Person
- India as a Location
- Panasonic as an Organization

NER enables this without manual input, making it easier to scale insights across large volumes of unstructured data. It is especially useful in fields like finance, legal tech, media monitoring, and customer service platforms.
In enterprise systems, NER can help extract customer names and case references from emails, flag locations in incident reports, or track mentions of products in feedback logs. It is also commonly used as a preprocessing step in more complex tasks like knowledge graph construction or intent detection.
6. Sentiment Analysis
Sentiment analysis is the process of evaluating a piece of text to determine its emotional tone, whether the message is positive, negative, or neutral. This technique helps organizations monitor opinions at scale, turning subjective feedback into structured insight.
The goal is not to understand what someone said, but how they feel about it. Sentiment analysis can be applied to customer reviews, survey responses, support interactions, or social media posts to detect dissatisfaction, enthusiasm, or indifference.
For example, a line like
“The support team resolved my issue quickly and politely”
Would be categorized as positive,
While “I’ve emailed three times and still no response”
Would be labeled negative.
Behind the scenes, sentiment analysis relies on models trained on annotated datasets. These models learn to associate patterns in word choice, structure, and tone with emotional weight. Some systems go further by breaking feedback down into specific topics (aspect-based analysis), or tracking degrees of sentiment (very negative, slightly positive, etc.).
In software development, sentiment analysis can support:
- Prioritization of support tickets based on tone
- Alerts for sudden changes in brand perception
- Dashboards that monitor feedback trends over time
Rather than reviewing messages one by one, teams gain an overview of sentiment patterns that inform product decisions, customer outreach, and risk management.
7. Text Classification
Text classification is the process of assigning categories to text based on its content. It allows software systems to organize unstructured language data into structured outputs that can be used for search, filtering, or automation.
This technique helps transform raw text into structured information that systems can search, group, or filter. It is widely used in customer service, content management, and internal tooling. Some common applications include:
- Flagging emails as spam or not spam
- Sorting user queries into billing, technical support, or account access
- Grouping feedback by topic, such as pricing, performance, or usability
- Routing tickets based on urgency, such as low, medium, or high priority
- Tagging documents by department, like legal, HR, or finance
In each case, the system assigns labels that help reduce manual sorting and improve response time. Text classification models are trained on labeled data and can process new input at scale with consistent logic.
8. Topic Modeling
Topic modeling is an unsupervised technique used to uncover themes within large volumes of text. Unlike classification, it does not rely on predefined categories. Instead, it groups related words based on how frequently they appear together, allowing the system to infer topics from patterns in the data.
This method is often applied when working with datasets that lack structure or labeled examples. It helps teams summarize, segment, or explore documents at scale without manually reading or tagging them.
For example, Discovering Topics in User Reviews
Imagine analyzing 5,000 customer reviews from an e-commerce platform. The reviews are unstructured and vary in phrasing, tone, and length.
A topic modeling algorithm might detect the following themes across the dataset:
| Topic Label | Top Keywords Detected |
|---|---|
| Shipping Issues | late, delivery, tracking, delay, courier, package |
| Pricing Concerns | expensive, price, value, cost, discount, deal |
| Product Quality | broken, durable, quality, material, defect, sturdy |
| Customer Support | support, response, agent, refund, help, wait time |
| App Experience | app, login, crash, update, slow, bug |
Even though these topics are not labeled in the raw data, topic modeling identifies clusters of related terms and assigns them to documents. This allows teams to:
- Quantify how often each theme appears
- Track shifts in topic frequency over time
- Prioritize issues based on topic volume and sentiment
This insight can guide product fixes, UX changes, or support process improvements — without requiring teams to manually label or read thousands of entries.
Each topic is represented as a cluster of frequently associated terms, and each document is treated as a mix of these topics. This makes it possible to understand what users are talking about even if the language varies widely between entries.
It is particularly useful in early discovery stages, where teams need to identify themes before deciding how to act on them.
Conclusion
Natural language processing techniques turn unstructured language into structured, usable data. From tokenization and classification to sentiment analysis and summarization, each method plays a role in making text easier to analyze, automate, and act on.
For teams building software products, internal tools, or data pipelines, these techniques offer practical ways to improve accuracy, reduce manual effort, and extract insights at scale. As more workflows rely on text — from customer feedback to compliance records — the ability to process language efficiently is becoming essential.
At Prioxis, we help teams integrate NLP into real systems, from proof of concept to production-grade implementation. If you're building something where language matters, we’d be glad to support you.
Let’s talk about what your system needs — and how to make it work.
