LLMs: Why Every Business Leader Must Understand Them Now
 Admin
Admin


Summarise with AI:
Artificial intelligence has worn many hats over the years: hype machine, disruptor, and now, a genuine business advantage. One of the technologies making the most noise, and delivering real results, is the Large Language Model, better known as the LLM.
They might sound intimidating at first, but the idea behind them is pretty easy to grasp. And if you are in a leadership role, understanding LLMs is quickly moving from “nice-to-know” to “must-have knowledge.”
This guide will walk you through what LLMs are, how they work, and where they can actually make a difference for your business.
What is a Large Language Model (LLM)?
A Large Language Model is an artificial intelligence system trained to understand and generate human language. It analyzes vast amounts of written material to learn patterns, structures, and relationships between words and ideas.
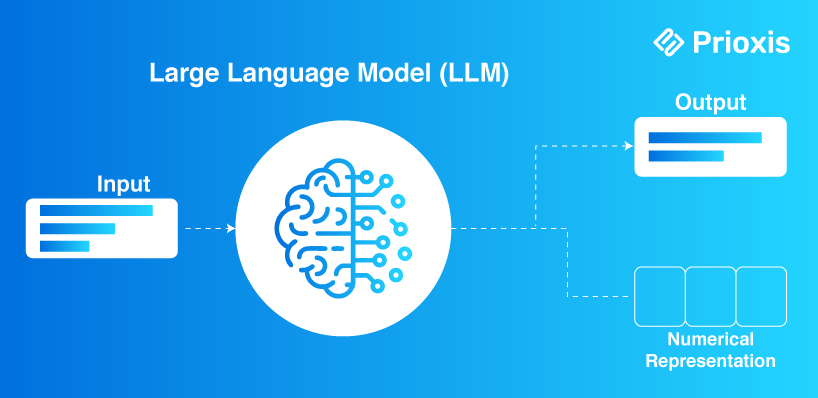
In a business context, LLMs can:
- Draft professional communications
- Summarize detailed reports
- Support customer service teams
- Assist with knowledge management across departments
An LLM essentially operates as a highly scalable, consistently available assistant for language-driven tasks. While LLMs are powerful, it is important to remember they do not "understand" language the way humans do. They are statistical models trained to recognize patterns, not to reason or think independently.
Different Types of LLMs
LLMs are not a one-size-fits-all technology. Different models are optimized for different types of work. Choosing the right type of LLM is critical depending on your objectives:
1. Generative LLMs
These models are designed to create new content from a prompt. When given an input, they generate text that is original yet contextually appropriate. Common use cases include content creation, marketing copy, personalized customer messaging, and chatbots.
2. Comprehension LLMs
Instead of creating new text, these models focus on understanding existing material. They are typically used to power search engines, document classification tools, and automated summarization systems. They help companies sift through large volumes of data quickly and accurately.
3. Instruction-tuned LLMs
These models are specifically trained to follow structured tasks or workflows. They interpret commands like "Summarize this document in five bullet points" or "Draft a response following this company style guide." Instruction-tuned LLMs are becoming critical in industries like legal services, healthcare, and enterprise automation. Choosing the right type of LLM depends on the specific task requirements, not just the model's size or reputation.
Deployment strategies should start with a clear match between the model's strength and the business requirement.
How LLMs Work?
LLMs predict language outcomes by recognizing patterns from their training data. When you provide an input, the model does not think about the meaning in a human sense. Instead, it analyzes the input and predicts the most likely next word based on its training. It repeats this word-by-word prediction until a full sentence, paragraph, or document is formed.
Key Mechanisms Inside an LLM:
- Tokenization Text is broken down into small pieces called tokens, often corresponding to words or word fragments.
- Context windows The model looks at a "window" of surrounding tokens to decide what should come next.
- Probability distribution At each step, the model ranks possible next tokens by likelihood and selects one based on the assigned probabilities.
Because of this design, LLMs can generate highly realistic and coherent text but can also occasionally make factual errors, known as "hallucinations," if the training data lacked clarity. LLMs do not verify information against reality during generation. They rely entirely on training data and prompt structure.
To see how LLMs are making an impact beyond theory, look at ours guide to real-world LLM use cases.
How LLMs Are Trained?
Training an LLM is a complex, multi-stage process that requires massive compute power and careful dataset curation.
- Pretraining The model is exposed to a wide range of general information sources.
- Fine-tuning Businesses adjust pretrained models to align with their industry, internal policies, and specific tasks.
- Continuous improvement Through real-world use, models are refined further to match evolving business needs.
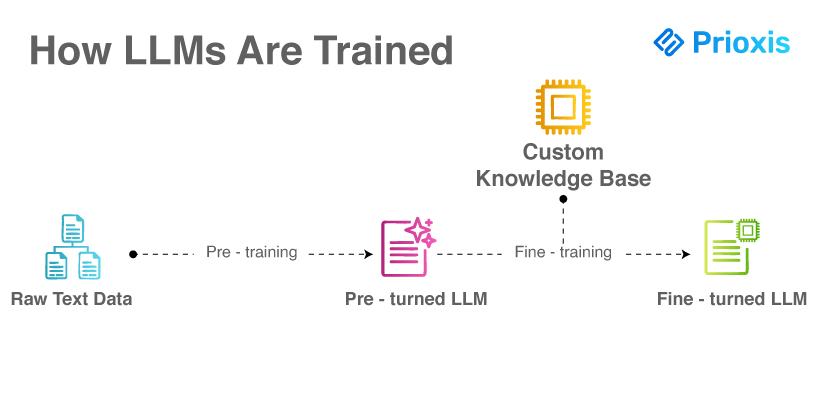
1. Pretraining
In the pretraining phase, the model learns general patterns of language. It processes a wide-ranging dataset including books, websites, encyclopedias, news articles, and more. The model tries to predict missing words in sentences and is rewarded for making correct guesses. This phase builds the foundation for basic grammar, facts, and reasoning patterns.
2. Fine-tuning
Pretrained models are powerful but general. Fine-tuning adapts them to specific industries, tasks, or company requirements. Fine-tuning datasets are smaller but higher quality, often including proprietary documents, regulatory standards, or domain-specific language (such as medical or legal terminology). Fine-tuning ensures the model speaks in the organization's tone, follows compliance rules, and understands sector-specific knowledge.
3. Continuous Learning and Evaluation
After deployment, LLMs must be monitored and improved over time. This includes feedback loops from users, regular evaluation against updated standards, and retraining on new or corrected data when needed. Continuous learning is crucial to prevent drift or degradation in model performance.
Advantages and Limitations of LLMs
Advantages
- Productivity Gains LLMs can automate repetitive language tasks, reduce human workload and accelerate output.
- Consistency Across Outputs Unlike humans, models do not tire or lose focus, ensuring a steady level of quality.
- Scalability Once deployed, a single model can support thousands of users and transactions simultaneously.
- Cost Savings Over Time Although initial investment is high, automating manual tasks can reduce labor costs over the long term.
Limitations
- Accuracy and Hallucination Risks Models can produce factually incorrect or misleading outputs. Every important output needs review before use.
- Bias and Ethical Challenges Models inherit biases from their training data. If not carefully managed, outputs can reflect or even amplify those biases.
- Infrastructure and Compute Costs Training and running large LLMs require significant cloud resources or on-premises hardware, raising operational costs.
- Security and Compliance Risks Sensitive information processed through LLMs must be handled carefully to prevent leaks, breaches, or regulatory violations.
LLMs are extremely capable but should be treated as powerful assistants, not decision-makers. Successful integration of AI depends on maintaining human supervision, particularly where compliance, branding, or client communication is concerned.
Conclusion: Focus on Purpose, Not Just Technology
Large Language Models are becoming a foundation technology for modern enterprises. Their ability to process, generate, and understand language at scale offers major advantages across industries. However, adopting LLMs successfully requires more than just technical deployment. Organizations must align LLM use with clear business goals, implement proper governance, fine-tune models for specific tasks, and maintain continuous human oversight. Companies that approach LLMs with strategic intent rather than chasing trends will gain the most sustainable value.
